LLM (ChatGPT, Gemini, Mistral…..) sono arrivati alla massima espansione? cosa ci sarà dopo? Diamo uno sguardo ai nuovi modelli LCM!!
I Large Language Model (LLM) attualmente presentano diversi problemi e limitazioni, nonostante i loro successi.
Questi problemi possono essere raggruppati in alcune aree principali, come evidenziato nelle fonti:
- Necessità di grandi quantità di dati: Gli LLM richiedono enormi quantità di dati per l’addestramento, e la disponibilità di tali dati sta diventando un problema. Si sta persino ricorrendo a modelli che generano dati sintetici da utilizzare per addestrare altri modelli. Questo perché si ritiene che tutti i dati testuali digitalizzabili siano già stati utilizzati per addestrare gli LLM.
- Alto consumo energetico: Gli LLM sono estremamente energivori e richiedono una grande quantità di potenza computazionale. Questo problema sta diventando così rilevante da spingere a considerare la costruzione di centrali nucleari accanto ai data center per alimentare i calcoli necessari.
- Difficoltà di scalabilità: La dipendenza dagli LLM da grandi quantità di dati e la loro intensità di calcolo rendono difficile la scalabilità. Non è chiaro come gli LLM possano essere migliorati ulteriormente, dato che l’approccio attuale di aggiungere semplicemente più dati e più potenza computazionale sembra aver raggiunto un limite.
- Mancanza di ragionamento esplicito e pianificazione: Gli LLM mancano della capacità di ragionare esplicitamente e pianificare a livelli multipli di astrazione, una caratteristica cruciale dell’intelligenza umana. Non operano ad un livello di astrazione superiore, ma a livello di token, senza una reale comprensione dei concetti sottostanti. Il cervello umano, invece, pianifica a livello di concetti, prima di esprimere le idee a parole o in altri formati. Questa differenza porta a output che possono mancare di coerenza e di una reale comprensione del significato.
- Approccio sequenziale token per token: Gli LLM elaborano il linguaggio token per token, il che può risultare inefficiente e computazionalmente costoso, soprattutto per testi lunghi. Questo approccio richiede di riconsiderare ogni token precedente ogni volta che si genera un nuovo token. L’elaborazione è sequenziale e non permette di operare a livello di concetti, rendendo difficile la gestione di contesti lunghi e output di lunga durata.
- Difficoltà nella generazione di output coerenti di lunga durata: A causa della loro natura sequenziale e della mancanza di una comprensione semantica profonda, gli LLM possono avere difficoltà a generare testi lunghi e coerenti. Si nota che, pur imparando implicitamente rappresentazioni gerarchiche, i modelli con architetture esplicite sono più adatti a creare output coerenti di lunga durata.
- Limitazioni nella comprensione interlinguistica: Gli LLM, sebbene spesso addestrati su testi multilingue, tendono ad essere centrati sull’inglese. Ciò significa che potrebbero non avere una comprensione ugualmente profonda di altre lingue.
- Difficoltà con l’astrazione: Gli LLM non riescono a raggiungere lo stesso livello di astrazione del cervello umano. Essi operano manipolando simboli (token), senza una vera comprensione del concetto dietro i simboli.
- Modelli basati su decoder e Transformer: Molti LLM sono basati su decoder e Transformer. Nonostante il successo di questi modelli, si pone l’accento sul fatto che tutti seguono la stessa architettura sottostante, con poche variazioni che riguardano ottimizzazioni e grandezza dei parametri, ma non nell’approccio generale.
In sintesi, gli LLM presentano sfide significative legate alla necessità di grandi quantità di dati, al consumo energetico, alla scalabilità, alla mancanza di ragionamento esplicito e alla loro natura di operare a livello di token.
Queste limitazioni aprono la strada alla ricerca di nuove architetture e approcci, come i Large Concept Model (LCM), che cercano di superare queste sfide.
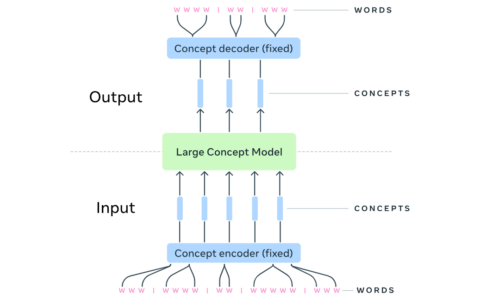
Invece di operare a livello di token, un LCM opera a un livello semantico superiore, utilizzando concetti come unità di base.
Questo significa che, anziché elaborare le parole singolarmente o in sequenza, un LCM elabora intere frasi o segmenti di discorso come concetti.
Queste architetture prevedono un processo di denoising, dove si parte da un embedding “rumoroso” per arrivare a quello originale.
Meta ha prodotto il primo paper e codice open su github (GitHub – facebookresearch/large_concept_model: Large Concept Models: Language modeling in a sentence representation space) in cui si vede che a parità del numero di parametri di addestramento si hanno risultati migliori con minor dispendio di calcolo (e quindi di energia), nativamente multilanguage e multimodale
1. Large Language Models (LLM)
- Definizione: Modelli di intelligenza artificiale addestrati su enormi quantità di dati testuali per comprendere, generare e manipolare il linguaggio naturale.
- Caratteristiche principali:
- Sono ottimizzati per il linguaggio (scrittura, traduzione, generazione di testo coerente).
- Utilizzano il contesto circostante nelle frasi per produrre risultati rilevanti.
- Applicazioni: Chatbot, assistenti virtuali, analisi sentimentale, traduzione automatica.
- Esempi: GPT (di OpenAI), BERT, T5.
- Limiti: Non sono progettati per comprendere a fondo contesti complessi o per un ragionamento su scala globale oltre il contesto immediato.
2. Large Contextual Models (LCM)
- Definizione: Modelli che mettono enfasi su un ragionamento più contestuale e globale, prendendo in considerazione molteplici fattori esterni rispetto al semplice linguaggio.
- Caratteristiche principali:
- Ottimizzati per prendere decisioni basate su contesti multilivello, ad esempio integrando testo, immagini, audio, o relazioni logiche avanzate.
- Ideali per compiti che richiedono una comprensione “del mondo reale”.
- Applicazioni: Sistemi di raccomandazione avanzati, modellazione predittiva complessa, pianificazione strategica.
- Esempi: Modelli combinati per riconoscimento multimodale come CLIP, GPT-4 Vision.
3. Creative Adversarial Networks (CAN)
- Definizione: Variante delle reti neurali generative avversarie (GAN – Generative Adversarial Networks) progettate per creare arte o design “creativi” e innovativi.
- Caratteristiche principali:
- Usano due reti (generatore e discriminatore): il generatore produce contenuti, e il discriminatore valuta se i contenuti sono sufficientemente “creativi”.
- Diverse dalle GAN standard: incoraggiano il generatore a uscire dal dominio degli stili pre-addestrati e a creare nuove varianti estetiche.
- Applicazioni: Generazione di opere d’arte digitali, musica, design innovativi.
- Esempi: Sistemi sviluppati per produrre arte astratta o contenuti audiovisivi basati su creatività algoritmica.
Sintesi delle differenze LLM/LCM/CAN
| Modello | Focus principale | Ambito d’uso | Punto di forza |
|---|---|---|---|
| LLM | Linguaggio naturale | Generazione e comprensione testo | Gestione di enormi quantità di dati testuali |
| LCM | Contesto e ragionamento globale | Decisioni complesse, sistemi multimodali | Considerazione multilivello del contesto |
| CAN | Creatività generativa | Arte, design, innovazione | Produzione di contenuti creativi e unici |
